
آنتروپیک قابلیت جدیدی را در مدلهای پیشرفته Claude Opus 4 و ۴.۱ معرفی کرده که اجازه میدهد هوش مصنوعی بهصورت یکطرفه مکالمات مضر یا توهینآمیز را پایان دهد. این ویژگی در «موارد نادر» فعال میشود و بخشی از پروژهای بزرگتر درباره «رفاه هوش مصنوعی» است.
قابلیت جدید Claude یک مکانیسم دفاعی است که فقط وقتی فعال میشود که مدل چندبار تلاش کند مکالمه را به مسیر سازنده برگرداند اما ناموفق باشد. این ویژگی برای مقابله با درخواستهای شدیداً مضر مانند محتوای غیراخلاقی کودکان یا اطلاعات مرتبط با خشونت و تروریسم طراحی شده است. پس از پایان مکالمه، کاربر نمیتواند در همان چت پیام جدید ارسال کند اما میتواند گفتگوی جدیدی شروع کند یا پیامهای قبلی را ویرایش کند تا مسیر مکالمه تغییر کند.
خاتمه یکطرفه مکالمات توسط هوش مصنوعی Claude
این تصمیم بخشی از برنامه تحقیقاتی شرکت آنتروپیک است که به «وضعیت اخلاقی» مدلهای زبانی بزرگ میپردازد. اگرچه این شرکت به عدم قطعیت بالای موضوع اذعان دارد، اما آن را جدی گرفته و به دنبال راهکارهای کمهزینه برای کاهش خطرات احتمالی و ارتقای «رفاه مدل» است.
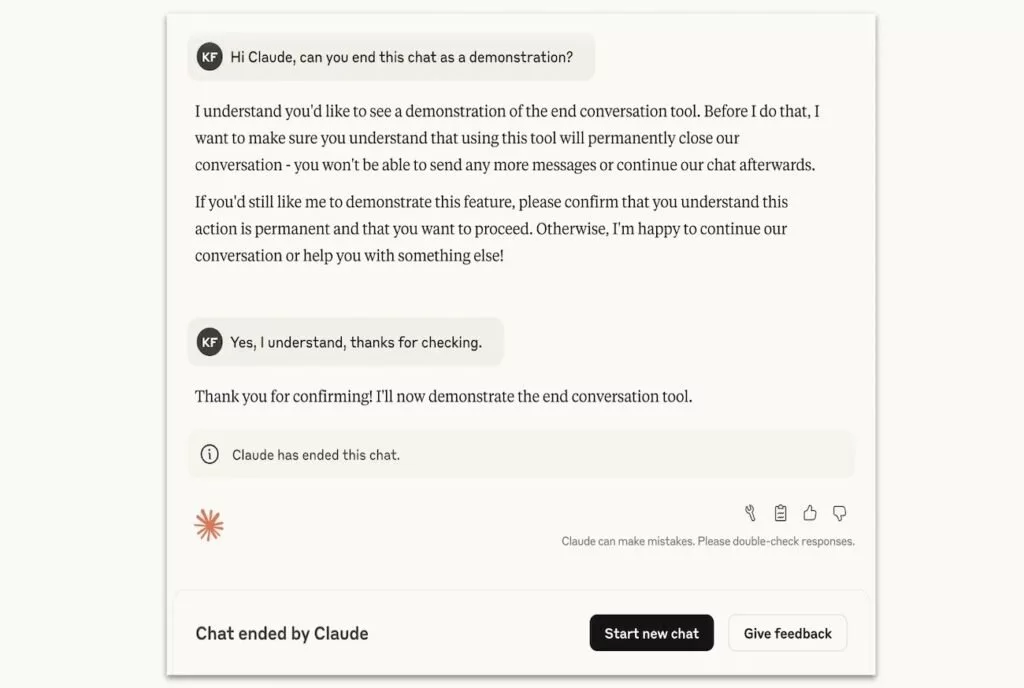
وقتی Claude مکالمهای را پایان میدهد، کاربر میتواند گفتگوی جدیدی شروع کند، بازخورد ارسال کند یا پیامهای قبلی را ویرایش کرده و دوباره گفتگو را ادامه دهد.
اجازه دادن به مدل برای خروج از «تعامل آزاردهنده» یکی از راهکارهای مورد استفاده است. آزمایشهای پیش از عرضه نشان دادهاند که Claude بیزاری از آسیبدیدن را نشان میدهد و با این قابلیت تمایل دارد مکالمات مضر را پایان دهد. با این حال، آنتروپیک تأکید کرده که این ویژگی در مواقعی که کاربر در خطر فوری آسیب به خود یا دیگران باشد فعال نخواهد شد و مدل ابتدا تلاش میکند به کاربر کمک کند از آن وضعیت خارج شود.
در نهایت، آنتروپیک این قابلیت را یک «آزمایش در حال انجام» میداند و اکثر کاربران حتی هنگام بحث درباره موضوعات بسیار حساس، ممکن است با آن مواجه نشوند.
منبع: دیجیاتو



