به نقل از شبکه
توسعهدهندگان برنامههای کاربردی در زمان ساخت برنامههای خود بسته به زبانی که از آن استفاده میکنند بدون آنکه اطلاع داشته باشند از یک مفسر یا کامپایلر استفاده میکنند. مفسرها و کامپایلرها به شیوه خود کدهای نوشته شده توسط برنامهنویسان را به کدهای قابل فهم کامپیوتری تبدیل میکنند. با اینحال کامپایلرها و مفسرها تفاوتهایی با یکدیگر دارند که در این مقاله بهطور اجمالی این موضوع را بررسی میکنیم.
کامپایلر چیست؟
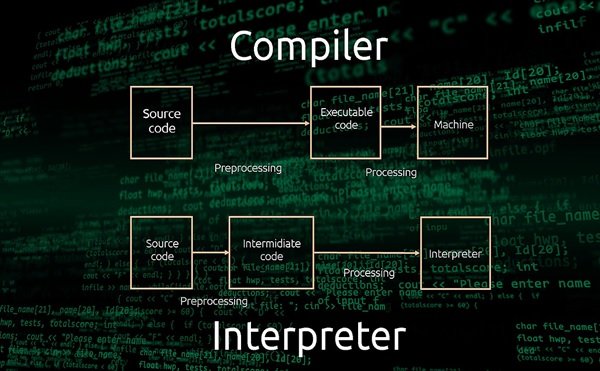
کامپایلر (Compiler) برنامه یا مجموعهای از برنامههای کامپیوتری است که متنی از زبان برنامهنویسی سطح بالا (زبان مبدأ) را به زبانی سطح پایین (زبان مقصد)، مثل اسمبلی یا زبان سطح ماشین، تبدیل میکند. خروجی این برنامه ممکن است برای پردازش شدن توسط برنامه دیگری مثل پیونددهنده مناسب باشد یا فایل متنی باشد که انسان نیز بتواند آن را بخواند. به این علت فرودبر نامگذاری شدهاست که کد با زبان سطح بالا را به کد زبان سطح پایین تبدیل میکند بدون این که در رفتار کد تغییری حاصل شود. به عمل compile کردن فرودش گفته میشود. مهمترین علت استفاده از ترجمه کد مبدأ، ایجاد برنامه اجرایی است. برعکس برنامهای که زبان برنامهنویسی سطح پایین را به بالاتر تبدیل میکند را مترجموارون گوییم. ترجمه کامل کد منبع برنامهای از یک زبان سطح بالا به کد شیء، پیش از اجرای برنامه را همگردانی یا کامپایل میگویند. به بیان ساده، کامپایلر برنامهای است که یک برنامه نوشته شده در یک زبان خاص ساختیافته را خوانده و آن را به یک برنامه مقصد (Target Language) تبدیل مینماید. در یکی از مهمترین پروسههای این تبدیل، کامپایلر وجود خطا را در برنامه مبدأ اعلام مینماید.
انواع کلی کامپایلر
تنوع کامپایلرها ممکن است به چشم نیاید. تعداد بسیار زیادی زبانهای منبع وجود دارند که دامنه آنها از زبانهای شناخته شده مانند فرترن و پاسکال تا زبانهای خاص منظوره گستردهاست. زبانهای مقصد نیز گستردگی متناظر با این زبانها دارند. یک زبان مقصد ممکن است زبان برنامهسازی دیگر یا زبان ماشین یا … باشد. کامپایلرها به انواع تکگذره، چند گذره، باردهی و اجرا، بهینهساز، غلطیاب و … بسته با عمل انجام شده تقسیم میشوند. علیرغم این تنوع اعمال اساسی که هر کامپایلر بایستی انجام دهد، مشابه هم میباشند. در اواسط دهه ۱۹۵۰ کامپایلرها به عنوان برنامههایی دشوار شناخته شده بودند. اولین کامپایلر فرترن، به عنوان مثال ۱۸ سال زمان برای طراحی صرف کرد. از آن زمان روشهای سیستماتیک برای استفاده از بسیاری اعمال مهم حین عمل کامپایل ابداع شدهاست. همچنین زبانهای پیادهسازی خوب، محیطهای برنامهنویسی و ابزارهای نرمافزاری مناسب ایجاد شدهاند. با کمک این پیشرفتها یک کامپایلر را میتوان حتی به عنوان پروژه درسی در یک ترم تحصیلی دانشجویی طراحی کرد.
کامپایلرهای Native و cross
اکثر کامپایلرها به دو دسته Native و Cross تقسیم میشوند. کامپایلرهایی که به منظور اجرای برنامهها کدهای باینری را تولید میکنند، کامپایلرهایی با کد محلی یا Native گوییم چرا که تنها در کامپیوترهای یک نوع با سیستمعاملهای یکسان قابل بهکارگیری است. از طرف دیگر ممکن است کامپایلرها کدهای باینری را تولید کنند که در سیستمهای مختلف قابل اجرا باشد. به این دسته از کامپایلرها که وابستگی به سختافزار ندارند، کامپایلرهای عبوری یا Cross گوییم. برای این نوع کامپایلرها تنها کافی است برای بار اول سختافزار را به آن معرفی نمود؛ بنابراین میتوان نتیجه گرفت که کامپایلرهای عبوری مفیدتر هستند. این تقسیمبندی برای مفسرها به کار نمیرود زیرا آنها از نمایش دودویی برای اجرای کد خود استفاده نمیکنند. ماشینهای مجازی در هیچیک از این دستهبندیها نمیگنجد. هر گاه در ماشینهای مجازی یکسان قابل اجرا باشد میتوان آن را Native و هرگاه کامپایلر قادر به تولید خروجی برای پلت فورمهای مختلف باشد آن را Cross گوییم.
کامپایلرهای تک مرحله و چند مرحله
فازبندی کامپایلرها که در پشت زمینه به محدودیتهای منابع سختافزاری وابستهاست. در نتیجه کامپایلرها به مجموعه برنامههای کوچکتر تقسیم میشوند هر یک بخشی از عمل ترجمه یا آنالیز را برعهده میگیرند. کامپایل تک فازی به نظر مفید میآید، چراکه سریعتر است. زبان پاسکال از این امکان استفاده میکند. اما مشکل اینجا است که اگر اعلان جلوتر از دستور بهکارگیری باشد، چه کار باید کرد؟ برای حل این مشکل میتوان در فاز اول اعلانها را مشخص کرد و در فاز بعد عمل ترجمه را انجام داد. عیب دیگر کامپایلر تک فازی دشواری بهینهسازی کدهای زبان سطح بالا میباشد. همگردان یکگذره (One-Pass Compiler) کامپایلری است که برای تولید کد ماشین، تنها یک مرتبه متن برنامه را میخواند. دستور برخی زبانها به گونهای است که تولید همگردان یکگذره برای آنها غیرممکن است. مجموعه همگردانهای گنو یا Gnu complier collection یا به صورت مخفف GCC مجموعهای از همگردانهای آزاد برای زبانهای برنامهنویسی است. تقسم بندی کامپایلرها به برنامههای کوچکتر تکنیکی است که همچنان مورد بحث محققان است. در این نوع دستهبندی کامپایلرها، انواع دیگری نیز وجود دارد: کامپایلر مبدأ به مبدأ که کدی با زبان سطح بالا را دریافت میکند و خروجی آن نیز زبان سطح بالا میباشد. مثلاً موازیسازی خودکار کامپایلر در مواردی که بهطور تکراری در برنامه ورودی وجود دارد و سپس تغییر شکلدادن کد و نوشتن کد یا ساختار زبانی موازی (برابر) با آن. (همچون دستور DOALL در فورترن). بسیاری از افراد زبانهای سطح بالا را به دو دسته تفسیری و کامپایلی تقسیم میکنند. کامپایلرها و مفسرها روی زبانها عمل میکنند نه زبانها روی آنها! مثلاً این تصور وجود دارد که الزاماً BASIC تفسیر میشود و C کامپایل. اما ممکن است نمونههایی از BASIC یا C ارائه شود که به ترتیب کامپایلری و تفسیری باشد. البته استثناهایی نیز وجود دارد، مثلاً برخی زبانها در خصوصیات خود این تقسیمبندی را مشخص کردهاند(C کامپایلری است یا SNOBOL۴ و اکثر زبانهای اسکریپتی که کد منبع زمان اجرا دارند تفسیری میباشد).
طراحی کامپایلرها
تقسیمبندی پروسههای کامپایل به مجموعهای از فازها مورد حمایت پروژه کامپایلری ((تولید کامپایلرهای باکیفیت))(PQCC) از دانشگاه Carnegie Mellon قرار گرفت. در این پروژه اصطلاحات جلو بندی، میان بندی (امروزه به ندرت به کار میرود) و عقب بندی معرفی شد. اکثر کامپایلرهای امروزی بیش از دو فاز دارند. جلوبندی معمولاً با پردازش املایی و معنایی شرح داده میشود. عقب بندی شامل تبدیل نوع و بهینهسازیهای مختلف میباشد. سپس کد برای آن کامپیوتر خاص تولید میشود. استفاده از جلوبندی و عقب بندی این را ممکن میکند که جلوبندیهای مختلفی برای زبانهای مختلف وجود داشته باشد و عقب بندیهای مختلفی نیز برای CPUهای مختلف.
جلوبندی به منظور تولید کد میانی یا IR از کد مبدأ استفاده میشود. جلوبندی معمولاً جدول نمادها را مدیریت نموده و یک نگاشت گر ساختمان دادهای، هر نماد را از درون کد مبدأ به اطلاعات مربوط به آن مثل نوع و دامنه تعریف آن نگاشت خطی میشود. این امر در چند فاز انجام میگردد:
خط نوسازی. زبانهایی که اجازه تعیین فضای اختیاری برای شناسهها را میدهند قبل از عمل تجزیه نیاز به فاز اضافی دارند که کد ورودی را به صورت متعارفی برای تجزیه گر آماده کند. Algol, Coral66, Atlas Autocode وImp نمونههایی از این زبانه هستند که به خط نوسازی (Line Reconstruction) نیازمند است.
پیش پردازش. برخی زبانها همچون C احتیاج به فاز پیش پردازش برای جایگزینی شروط کامپایل و ماکروها دارند. در زبان C فاز پیش پردازش شامل مرحله تحلیل لغوی میشود.
تحلیل لغوی کد متنی مبدأ را به اجزای کوچکی که نشانه(token) نامیده میشود میشکند. هر نشانه واحد سادهای از زبان است مثل کلمات کلیدی و نام نمادها. نحو نشانهها نوعاً یک زبان باقاعده است، بنابراین یک ماشین حالت متناهی که برپایه یک عبارت باقاعده بنا میشود میتواند جهت شناخت آن استفاده شود.
تحلیل نحوی شامل تجزیه کردن نشانههای مرتب جهت شناخت ساختار نحوی زبان میباشد.
تحلیل معنایی فازی است که معنای برنامه را جهت رعایت قوانین زبان بررسی میکند. یک مثال برای این فاز کنترل نوع است.
عقب بندی
گاهی مرحله عقب بندی با مرحله تولید کد اشتباه گرفته میشود. اما میتوان گفت که عقب بندی به مراحل چند گانه زیر تقسیم میشود:
تحلیل کامپایلر: این پروسه برای بدست آوردن اطلاعات بیشتر از نمایش میانی فایلهای ورودی میباشد. تحلیلگر نوعی تعاریف مختلفی دارد همچون تحلیلگر حلقوی، تحلیلگر وابسته، تحلیلگر مستعار، تحلیلگر اشارهای یا غیره میباشد. تحلیل دقیق زیر بنای هر کامپایلرهای بهینهاست. گراف فراخوانی و نمودار جریان کنترل معمولاً در فاز تجزیه تولید میگردد.
بهینهسازی: نمایش میانی زبان به معادلهای پر سرعت تر با شکلهای کوتاه تری تبدیل میگردد. از بهینهسازهای محبوبتر میتوان به موارد زیر اشاره نمود: توسعه درون خطی، حذف کدهای مرده، انتشار ثوابت، تبدیل حلقهها، تخصیصهای ثباتی و موازیسازی خودکار.
تولیدکننده کد: زبان میانی تغییر کرده به زبان خروجی مثل زبان ماشین ترجمه میشود. این شامل تخصیص منابع و تصمیمات ذخیرهسازی است، مثلاً اینکه کدام متغیر به رجیسترها یا حافظه اختصاص یابد و گزینش و زمانبندی دستورهای مناسب ماشین. البته در ابتدای امر که درباره زبانهای تفسیری و کامپایلری گفته بودند باید خاطر نشان کرد که زبانهای تفسیری خط به خط خوانده شده و اجرا میگردد در حالیکه در کامپایلری ابتدا تمام برنامه ترجمه شده و سپس اجرا میگردد پس در زمان اجرا سرعت اجرا شدن زبانهای کامپایلری بیشتر است. اما کشف و تصحیح خطا در تفسیری بهتر و راحت تر است.
GCC از ابتدا مخفف Gnu C Compiler بود ولی از زمانی که توانست زبانهای دیگری غیر از C از قبیل C++,Ada,Java,Objective C و Fortran را کامپایل کند به Gnu Compiler Collection تغییر نام داد. پدید آورنده اصلی GCC ریچارد استالمن است کسی که بنیانگذار پروژه Gnu محسوب میشود. نخستین نسخه GCC در سال ۱۹۸۷ انتشار یافت که یک پیشرفت مهم محسوب میشد زیرا محصول جدید اولین کامپایلر بهینهسازی شده قابل حمل ANSI C به عنوان یک نرمافزار آزاد محسوب میشد. در سال ۱۹۹۲ نسخه ۲٫۰ کامپایلر GCC عرضه شد. نسخه جدید قابلیت کامپایل کدهای ++C را نیز داشت. در سال ۱۹۹۷ یک انشعاب آزمایشی در GCC به نام EGCC به منظور بهینهسازی کامپایلر و پشتیبانی کامل تر از ++C ایجاد شد. در ادامه EGCC به عنوان نسل بعدی کامپایلر GCC پذیرفته شد و تکامل آن باعث انتشار نسخه سوم GCC در سال ۲۰۰۴ گردید. چهارمین نسخه از کامپایلر GCC در سال ۲۰۰۵ عرضه شد.
مفسر چیست؟
یک مفسر (Interpreter) در علوم کامپیوتر، یک برنامه کامپیوتری است که دستورهای نوشته شده در یک زبان برنامه نویسی را اجرا میکند. با وجود اینکه تفسیر کردن و ترجمه کردن، دو وسیله اصلی هستند که از طریق آنها زبانهای برنامهنویسی اجرا میشوند، دو مقوله کاملاً مجزا نیستند. یکی از دلایل این است که اغلب سیستمهای مفسر برخی از کارهای ترجمه را انجام میدهند. یک مفسر میتواند برنامهای باشد که مستقیماً کد منبع را اجرا میکند، کد منبع را به یک رابط میانجی مناسب (کد) تبدیل میکند و بلافاصله آن را اجرا میکن و از آن کمک گرفته میشود تا کدهای آماده به اجرایی که توسط مترجم -که قسمتی از سیستم مفسر است- ساخته شده را اجرا کند. پرل، پایتون، روبی و متلب همه نمونههایی از نوع ۲ هستند، در حالی که پاسکال و ماشین مجازی جاوا نوع ۳ هستند. برنامههای نوشته شده با جاوا از قبل ترجمه شده و به عنوان کدهای مستقل از ماشین، ذخیره میشوند و بعد در زمان اجرا توسط یک مفسر (ماشین مجازی) اجرا میشوند. برخی سیستمها، مانند اسمال تاک و غیره ممکن است ترکیبی از نوع ۲ و ۳ باشند. لفظهای زبان مفسر و زبان مترجم صرفاً به این معنا هستند که اساس پیادهسازی یک زبان برنامهنویسی یک مفسر است یا یک مترجم؛ یک زبان سطح بالا زبانی است که مستقل از پیادهسازی مشخصی است.
عملکرد
عیب اصلی مفسرها این است که برنامهای که تفسیر میشود، نسبت به برنامهای که ترجمه شود، دیرتر اجرا میشود. تفاوت سرعت میتواند ناچیز یا زیاد باشد. اغلب در مرتبه بزرگ و شاید بیشتر. غالباً اجرای یک برنامه تحت یک مفسر نسبت به اجرای کد ترجمه شده وقت بیشتری نیاز دارد. امّا مدت زمان تفسیر یک برنامه از مجموع زمان لازم برای ترجمه کردن و اجرا کردن آن، کمتر است. این موضوع هنگام نمونهسازی و تست کردن کد اهمیت ویژهای پیدا میکند. زیرا یک عملیات ویرایش-تفسیر-خطایابی میتواند کوتاهتر از عملیات ویرایش-ترجمه-اجرا-خطایابی باشد. تفسیر یک کد کندتر از اجرای کد ترجمه شدهاست، زیرا مفسر باید هر دفعه که برنامه شروع به اجرا میکند، همه عبارتهای آن را تحلیل کند و سپس عملیات مورد نظر را اجرا کند در حالی که کد ترجمه شده فقط عبارتها را اجرا میکند. این تحلیل زمان اجرا تحت نام «بالاسری تفسیری» نامیده میشود. دسترسی به متغیرها نیز در مفسر کندتر است. زیرا مسیردهی شناسه به محل ذخیرهسازی در زمان اجرا نسبت به زمان ترجمه به دفعات بیشتری صورت میگیرد.
برخی سیستمها به کدهای ترجمه شده و تفسیر شده اجازه میدهند تا یکدیگر را فراخوانی کنند و متغیرهایشان را به اشتراک بگذارند. به این معنا که هنگامی که یک روال تحت یک مفسر مورد تست قرار گرفت و اشکالزدایی شد، میتواند ترجمه شود و بنابراین، در حین اینکه روالهای دیگر در حال تولید شدن هستند، اجرای سریعتری داشته باشد. تعداد زیادی از مترجمها کد منبع را همان گونه که هست اجرا نمیکنند بلکه آن را به نوع فشرده تر داخلی تبدیل میکنند. برای مثال، برخی از مفسرهای ابتدایی، کلمات کلیدی را با نشانههای تک بایتی -که میتوانند برای یافتن دستورالعملها در یک میز جامپ استفاده شوند- جایگزین میکنند. یک مفسر ممکن است از همان نوع تحلیل گر واژگانی و تجزیهکنندهای استفاده کند که مترجم از آن استفاده میکند و سپس درخت انتزاعی ترکیب را تفسیر کند.
مفسرهای بایت کد
طیفی از احتمالات بین تفسیر کردن و ترجمه کردن وجود دارد که به مقدار تحلیل انجام شده قبل از اجرای برنامه بستگی دارد. برای مثال، ایماکس لیسپ به بایت کد -که نماینده بسیار بهینه شده و فشرده شدهای از منبع لیسپ است، ولی کد ماشین نیست (و در نتیجه وابسته به سختافزار مشخصی نیست) -ترجمه میشود. این کد «ترجمه شده» بعداً توسط یک مفسر بایت کد -که خود آن توسط زبان سی نوشته شدهاست- تفسیر میشود. کد ترجمه شده در این حالت، یک کد ماشین برای یک ماشین مجازی است، که در سختافزار پیادهسازی نشده و در مفسر بایت کد پیادهسازی شدهاست. همین شیوه در کد فورت -که در سیستمهای میان افزار باز استفاده میشود- به کار برده میشود: زبان منبع به «اف کد» (یک بایت کد) ترجمه میشود، که بعداً توسط یک ماشین مجازی تفسیر میشود.
مفسرهای درخت انتزاعی ترکیب
در طیف بین تفسیر کردن و ترجمه کردن، روش دیگری نیز وجود دارد. در این روش، کد منبع به یک درخت انتزاعی ترکیب بهینه شده تبدیل میشود و سپس به تبعیت از این ساختار درختی، برای اجرای برنامه اقدام میشود. در این روش هر عبارت فقط باید یک بار تجزیه شود. به عنوان یک مزیت نسبت به بایت کد، این روش ساختار برنامه سراسری و رابطه بین عبارات را (که در بایت کد از بین میرود) حفظ میکند و یک نمایش فشرده تر را فراهم میسازد؛ بنابراین، درخت انتزاعی ترکیب، به عنوان یک قالب میانی بهتر نسبت به بایت کد برای مترجمهای داخل زمانی پیشنهاد شدهاست. همچنین این روش اجازه میدهد، در زمان اجرا تحلیل بهتری انجام گیرد. ثابت شدهاست که یک مفسر جاوا مبتنی بر درخت انتزاعی ترکیب، از یک مفسر مشابه مبتنی بر بایت کد سریع تر است. این سرعت بیشتر به خاطر بهینهسازی قویتر است که این بهینهسازی به دلیل برخورداری از ساختار کامل برنامهٔ موجود در حین اجرا، به وجود میآید.
ترجمه داخل زمانی
ترجمه داخل زمانی باعث کم شدن فاصله بین مفسرها، مفسرهای بایت کد و مترجمها شدهاست و تکنیکی است که در آن بایت کد در زمان اجرا به شکل کد ماشین بومی ترجمه میشود. این برمی گردد به کارایی اجرای کد بومی در سریع کردن زمان بالا آمدن و افزایش استفاده حافظه، هنگامی که در ابتدا بایت کد ترجمه میشود. بهینهسازی توافقی یک تکنیک ترکیبی ای هست که در آن مفسر، برنامه در حال اجرا را شکل میدهد و قسمتهایی که بیشتر استفاده شدهاند را به کد بومی ترجمه میکند. هر دو تکنیک بیش از چند دهه سن ندارند، بهطوریکه نخستین بار در زبانهایی مانند اسمال تاک در ۱۹۸۰ بکار برده شدند. ترجمه داخل زمانی در سالهای اخیر، توجه بسیاری از مهندسان نویسنده زبانهای برنامهنویسی را به خود جلب کردهاست. بهطوریکه هماکنون جاوا، پایتون و چارچوب دات نت از این تکنیک استفاده میکنند.